The previous notes introduced databases and DBMS’s while mentioning that this course would focus on relational databases. Relational databases are the most common kind of database even though they are quit old. Most websites ranging from small ones like this one to gigantic ones like FaceBook use relational databases to store much of the data that is displayed on the page. Most mid-size to large companies keep track of their employee and customers records using relational databases. Similarly, many medical records are stored in relational databases. They are everywhere, and they are important, so we need to learn about them!
Records and Relationships
One point that was mentioned in the previous notes but not followed up on was that we saw how to use basic arrays to store one kind of information, like a list of integers, but we’d have to use a different approach to store multiple values of different types. Now we can address that problem, too, and see how relational databases can store multiple pieces of most any kind of information. The fundamental idea behind the approach is we assume the only reason we have to store multiple pieces of information together is that those pieces are all related to each other; they are all describing the same thing.
For instance, a hospital or medical office may keep track of a name, social security number (SSN), date of birth (DOB), and an address for each patient. For each of these things, we would also have a specific data type in mind, say strings for name and address, int for SSN, etc. Such a collection of pieces of data that are all related to each other is an example of a record. The 4 pieces of data are related because they’re all describing the same person. A record for a patient wouldn’t include my SSN and your DOB because those two pieces are about different people–they’re not related. A record about you would include your SSN and DOB while a record about me would include mine. The items of information that are related are often called attributes. We would say there is a username attribute, an SSN attribute, etc. For each attribute, we can specify or include the type, too, but types are omitted for the rest of these notes to focus on the other details.
The definition of the patient record above is pretty basic, and it doesn’t include any actual data for a patient! It’s just names for the values we record for each one. Since we’re likely to keep track of more than one patient in a medical office, we’ll have more than on patient record. The abstract description above becomes concrete when we have info for multiple patients.

The more patients we have, the more redundant or annoying it will be to keep labeling all the values by the same attributes over and over. It’s typical to separate out the attribute names and just write them once as a label for the values for each different patient. When we do that, it looks like this:
| SSN | Name | DOB | Address |
| 111223333 | Max Powers | 1/11/1984 | 123 Fake St. |
| 444556666 | Taylor James | 2/22/1995 | 456 The Bowery |
| 777889999 | John Wick | 3/33/2006 | 789 Heaven Ln. |
In database terminology, there’s a fancy name for this object–a table. A table is generically something that has rows and columns where any particular row and column define a cell that can hold a value. You can create these kinds of tables in MS Word or soup them up with formulas and actions in an Excel spreadsheet. Many databases store data in tables, and tables are the building blocks of the relational data model. After learning about tables, we’ll move on to deal with the full relational model.
In a relational database, a table consists of rows and columns, but it’s more structured than that. Each row is a record, so all the values in a row are related to each other because they all belong to the same record. The table itself will have a name, and the attribute names will act like column headings in the table. Each “cell” in the table denotes a particular attribute’s value (labeled by the column name) for the record in that row. Cell is in quotes in the previous sentence because it’s not really database terminology. It’s spreadsheet terminology that has become commonly-used with generic tables, too, but not so much with database tables.
There are other sets of vocabulary that are commonly used with databases and database tables. They are summarized in the table (how ironic) below.
| Table | Row | Column |
| Record | Value or Attribute | |
| Relation | Tuple | Attribute |
| Entity Set | Entity | Attribute |
So a table is the basic structure in a database. It’s the building block. It’s column headings define the attributes for the record that table stores, and each row includes values for a different record that is stored. We’ll work with small databases that are easy to look at and think about where the tables have a few to several rows. It’s not uncommon to have tables with millions or billions of rows in the real world, so this simple idea of storing records this way turns out to be very powerful in practice.
Relationships between tables
A relational database contains one or more tables, and each table is used to store records. So a relational database provides a way of storing as many records as needed for whatever its purpose is. A medical office may have records relating to patients, bills, office visits, insurance payments, and of course the actual medical records of its patients.
A relational database is not just a group of tables, though, for there are often relationships that connect records together. A medical bill is related to the patient that incurs that expense. An insurance payment may be related to the patient and the bill. A bill is related to an office visit, and patients are also related to their office visits. Beyond being a group of tables, the relational data model contains a way to represents these common relationships between records.
The first step in describing how records may be related involves recognizing that some attributes or columns in a table may have important constraints they must obey. In the Patients table, since every row corresponds to an individual, we know that no two rows would have the same value in the SSN column because two different people shouldn’t have the same SSN. We call the SSN the primary key of the Patients table because every row must have a unique value of that attribute. Declaring a column to be the primary key constrains the data that is allowed in the table. If we try to introduce a new patient with the same SSN as an existing one, the database can warn us that the constraint has been violated or even prevent us from adding the data.
This uniqueness of the primary key is true no matter how many patients we keep track of. The utility of this kind of column is that it gives us a way to refer to any particular patient using the shorthand of their social security number. There will be only one row corresponding to a particular SSN, and since the values in a row are related as part of a record, that one SSN value can refer to or stand in for the entire set of values. We can use 777889999 to refer not just to someone’s SSN, but to John Wick, born on March 33, 2006, residing at 789 Heaven Ln.
| SSN | Name | DOB | Address |
|---|---|---|---|
| 111223333 | Max Powers | 1/11/1984 | 123 Fake St. |
| 444556666 | Taylor James | 2/22/1995 | 456 The Bowery |
| 777889999 | John Wick | 3/33/2006 | 789 Heaven Ln. |
SSN’s aren’t the only way to have a primary key column. We can always have a column that just counts rows 1,2,3,… and then the row number can act as a primary key. DBMS’s will typically auto-generate columns like this for us in a table if we specify. Its also possible for more than one column to be the primary key, and in that case the table is said to have a composite key. With a composite key, the values in any particular column might appear in other rows; they don’t have to be unique individually. But the combination of values from all the columns in the composite key will always be unique.
Now that we have the notion of primary keys, we can work out how to relate tables to each other. Let’s imagine the Bills table has a date and an amount, and we know it needs to also refer to the patient that owes the bill. We’ve already seen we can represent the patient by the primary key, their SSN, so the shortest easiest way to indicate which patient in a row of the Bills table is to have the ssn of the patient owing the bill in a column, too.
| ID | SSN | Date | Amount |
|---|---|---|---|
| 1 | 111223333 | 3/07/2024 | 150 |
| 2 | 777889999 | 4/08/2024 | 200 |
| 3 | 777889999 | 5/09/2024 | 250 |
| 4 | 111223333 | 6/10/2024 | 500 |
Looking at the Bills and Patients tables above, we can use the relationship that a Bill corresponds to a Patient to interpret the information. The first Bill for $150 from March 7, 2024 is for Max Powers, because the Bills row and the Patients row both have Max Powers SSN in them. We can do the same for the next two Bills for John Wick by matching up that SSN. Not all patients have to have a Bill, so it’s ok that Taylor james’ SSN doesn’t appear in the Bills table.
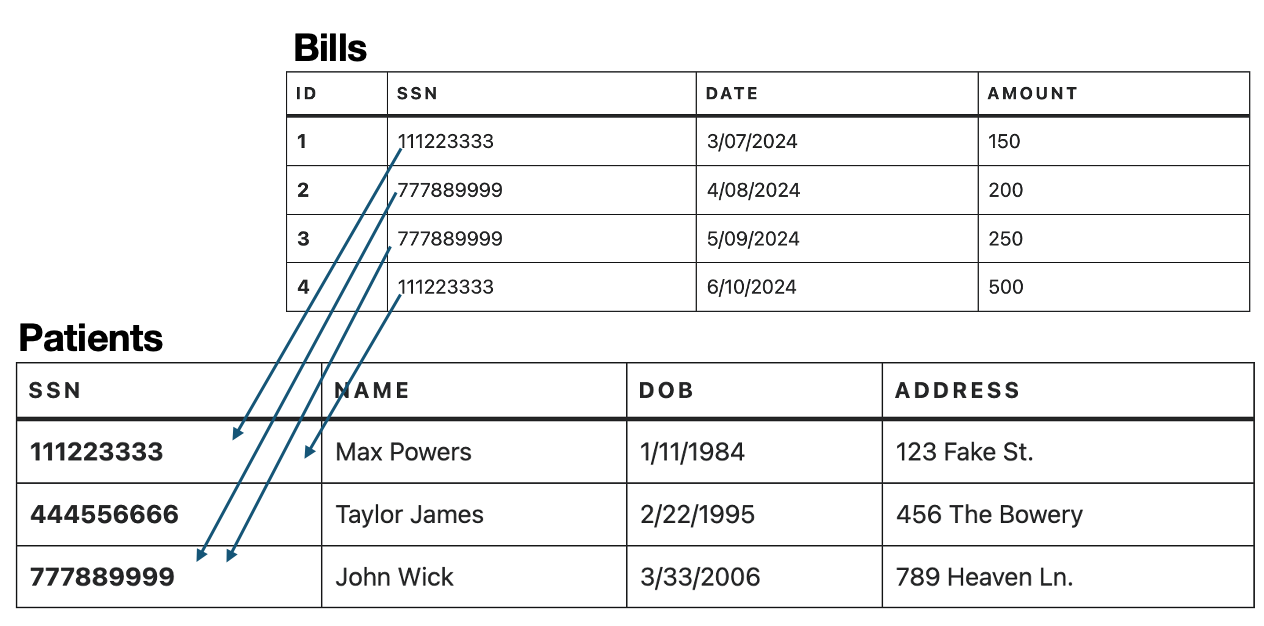
Here’s a summary of how that Bills – Patients relationship worked. We know that any row with such a column will refer to exactly one row in the Patients table because of the uniqueness of the primary key. By copying values of the primary key in another table, we can take advantage of that uniqueness and refer to rows in a different table. Such a column that can refer to other rows in that way is called a foreign key, and we would say that the foreign key column in the Bills table references the SSN column of the Patients table. By having foreign keys reference primary keys, we generate what’s called a key pairing or primary key-foreign key pairing between two tables. Key pairings are how relationships between tables are handled in the relational data model.
Finally, note the Bills table has an ID column. This column seems to be an index for the row number, and it’s there to act as the primary key for the table. The SSN can be the primary key of the Patients table just fine, but it wouldn’t work as the primary key here because the same individual is likely to be billed more than once over time. Their SSN would show up in multiple rows like we see above, so it can’t be unique by itself. Similarly, we expect that Data won’t work because we might see more than one bill per day. Likewise, more than one bill could be for the same amount. Even in this instance where we won’t see Date or Amount values being duplicated, we can’t infer from the data that it’s the primary key. We have to know what rules any data that could be in that table will obey, and use those constraints to determine the primary key column.
Relational Data Model
We can now summarize the relational data model and define what a relational database is. A relational database is a database that uses the relational data model. The relational data model describes a database that is a collection of tables where each table has a name and stores a certain type of record. For each table, the columns are the attributes of the record. They column names and data types for that table will all be specified. Moreover, each table will have a primary key, one or more columns whose value is unique in each row in that table. A table with unique rows in this fashion is more properly called a relation, and this vocabulary word is where the term relational data model gets its name. In other words, a relational database is a collection of relations. Moreover, the tables may have foreign keys which reference primary keys, indicating relationships between the tables involved.
The vocabulary list below indicates to us the big-picture view of a relational database. It’s one where each table has a primary key. The records that each table stores may be related to other records in the database, and if that is the case, there will be foreign keys, too.
| Term | Definition |
|---|---|
| Primary Key | One or more columns in a table that can be used to uniquely identify a row. In other words, the value(s) of the primary key column(s) cannot be duplicated in that table. |
| Foreign Key | One or more columns in a table that can be used to refer to another row because those values in the other table uniquely identify a row. The foreign key usually references the primary key of a table, but there are some exceptions. |
| Composite Key | A key that contains more than one column. |
| Relation | A table where each row is unique. That is, a relation is a table that has a primary key. |
| Relational Data Model | A logical data model where the database is a set of relations. Each relation stores one kind of record. Typically there will be foreign keys indicating relationships between the records. |
Schema Diagrams
The description of the relational model above boiled down to “name tables and columns and indicate the keys”. That’s the most important info that describes what kind of data a particular relational database can store. This information about the data it can store but not including any particular data is called the schema. It’s a basic definition or description of what kind of information any particular database might store.
It’s important to be able to communicate the schema or structure of a relational database to someone else. You may have a database design for a new app that other people running that app need to create; or you may be publishing a new open source medical records systems and need to let people know your data model. In either case, a typical way to communicate the structure is by sharing the schema with them. There are two common ways to share schemas. One is informal and is called a schema diagram. The other is more formal and involves sharing code writte in SQL. The Structure Query Language (SQL) is the language or relational databases, so it’s the most detailed way to communicate the schema. If you share the SQL, someone can execute it in the DBMS and then have a working version of the database. If you share just the schema diagram, the would have to write the SQL statements; they may end up with an equivalent but not necessarily identical database depending on how much information you put in the schema diagram. In particular the “visual syntax” we’ll see for schema diagrams doesn’t include the type of data stored in each column in a table. The SQL version would include those details, and many other forms for schema diagrams include that info, too.
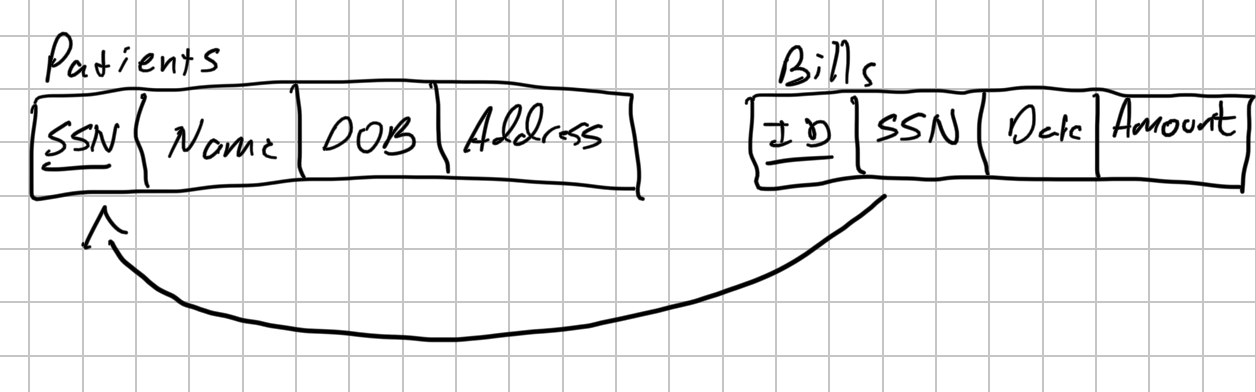
The informal version of schema diagrams we’ll use in this class shows the names of tables and each column in a table. It also indicates the primary of each table by underlining the column name(s). Foreign keys are also indicated by drawing arrows from the foreign key to the primary key. Below is the schema diagram for the Patients – Bills database.
The rules for our “house style” of schema diagram are:
- Show the name of the table
- Show the names of the table’s columns in a box below the table name. Optionally, we could also include the type of each column. For instance Name (Text), ID (Integer), and so on.
- Underline each table’s primary key column(s)
- Indicate foreign key column(s) by drawing an arrow from the foreign key to the column(s) it references. The foreign key is the tail of the arrow; the column(s) referenced are the tip of the arrow.
Supplemental Info – Optional
Reasons for the relational model
To justify why the relational model is the way it is, let’s imagine a database where we put all the information into one big table. We’ll end up with something that looks like
| ID | SSN | Date | Amount | NAME | DOB | Address |
|---|---|---|---|---|---|---|
| 1 | 111223333 | 3/07/2024 | 150 | Max Powers | 1/11/1984 | 123 Fake St. |
| 2 | 777889999 | 4/08/2024 | 200 | John Wick | 3/33/2006 | 789 Heaven Ln. |
| 3 | 777889999 | 5/09/2024 | 250 | John Wick | 3/33/2006 | 789 Heaven Ln. |
| 4 | 111223333 | 6/10/2024 | 500 | Max Powers | 1/11/1984 | 123 Fake St. |
| 5 | 444556666 | NULL | NULL | Taylor James | 2/22/1995 | 456 The Bowery |
| 6 | 111223333 | 7/11/2024 | 350 | Max Powers | 1/11/1984 | 123 Fake St. |
| 7 | 123456789 | 7/12/2024 | 275 | Morpheus | 2/29/1984 | 1 Dream Ave. |
Such a table is called a supertable. We could make it ourselves from the sailorsReservesBoats database by joining all three tables together, so it’s possible to get this information from the relational model. But here with the supertable, we have all the information right in front of us. Is that better or worse than having it split up into separate tables with foreign keys that lets us match the rows up back together?
It turns out it’s worse because it leads to redundancy. The same information appears in more than one place in the supertable. For instance every time Max Powers is billed, we see the full set of patient information (name, SSN, DOB, address) for poor Max. It’s stored redundantly, appearing 3 times when 1 would suffice. At a minimum it’s inefficient to use this extra storage space to duplicate data. Real database tables often have thousands, millions, or billions of rows, taking up terabytes or more of storage. Using unnecessary space can be costly, slow, and limit the amount of data that can be stored.
Some more subtle problems of redundancy were grappled with by Codd, Boyce, and others in the early days of the relational model. They considered the consequences of unintended situations that can arise if redundancy is not carefully managed. These situations are called anomalies and classified them as
- Insertion anomaly – problems when adding data
- Update anomaly – problems when changing data
- Deletion anomaly – problems when removing data
To understand these anomalies, imagine we want to add a new patient to the supertable. Since a new patient wouldn’t have yet been billed, we would have to leave much of the row empty–an insertion anomaly. This is actually allowed, but it seems odd to store a row with so much missing info. In fact, Taylor James is just such a patient above, and the SQL keyword NULL is snuck into the supertable to communicate that missing info. If we used two tables like the relational model demands, every new patient becomes a row in the Patients table. If that patient is not billed yet, we simply do not add a row to Bills referencing that patient.
In the same way, if we need to change John’s record to update his address, we would have to change it in multiple places. It’s very likely if humans were updating the data that mistakes would be made, and then the different John Wick rows may show different addresses by accident. Which row would then represent the truth? That confusion is an update anomaly. A deletion anomaly could arise in a similar way if we delete the bill for Morpheus. That patient appears in only one row, so if we delete that row, then the patient’s info vanishes, too! Deleting a bill should not also delete the patient.
The relational model addresses these anomalies because there is only one row for each Patient or Bill. Deleting a Bill simply involves removing a row from the Bills table. Adding a Patient simply involves adding a row to the Patients table without having to worry about associated bills. Changing a Patient or Bills values simply involves editing the one row in the table corresponding to the record that needs to be changed. The relational model solves the issues of redundancy by decomposing the supertable into separate relations. The decomposition is called a lossless decomposition because foreign key constraints allow us to rebuild the supertable whenever we need to.