We’ve seen that a relational database is a collection of tables where each table stores the same kind of records in its rows. Every table will have a unique attribute or set of attributes called the primary key that can act as a shorthand for the entire row. Foreign keys can use this shortand in other tables as a way to refer to a particular row, and in this way the different tables and records in a relational database can have relationships between them.
With all that abstract data model stuff out of the way, we need to actually be able to create and then use a relational database. The primary way of describing the tables and keys or getting data from them is to use the Structured Query Language (SQL, pronounced like the 3 letters and NOT pronounced like “sequel”). Virtually all relational databases understand SQL although there are small differences between them. For instance we’ll see that SQLite databases support fewer data types than MySQL databases do.
SQL contains different parts called sublanguages, the three most relevant of which are shown below. “Sublanguage” makes them sound more complicated than they are. Each sublanguage consists of only a few SQL statements, so it’s basically just a way to categorize the different things SQL lets us do. These things include creating tables, changing the schema by adding columns to a table, say, or querying the database to retrieve information stored in the tables. SQL is a very old language, and a common convention from days past is to put SQL in ALL CAPS, as you can see in the table, too.
| SQL sublanguage | Purpose | SQL statements |
| DDL – Data Definition Language | Define table names, column names, and constraints Add, change, or remove column names and/or constraints | CREATE TABLE ALTER TABLE |
| DML – Data Manipulation Language | Add data to tables Remove data from tables Change data in tables | INSERT INTO DELETE FROM UPDATE |
| Query Language | Return responses to information needs | SELECT FROM WHERE |
The SQL DDL
The SQL DDL is the SQL Data Definition Language. It’s purpose is to define the schema or to change the schema. The main statement, and the only one emphasized in this course, is the CREATE TABLE statement. The basic idea behind the CREATE TABLE statement is that you immediately provide the name of the table being created. After the name of the table, the columns, their domains, and any constraints are defined within a set of “()”. In programming, any “(” must have a matching “)”, so be sure to not forget the closing “)”. In general, each piece of information in the () is separated by commas.
In these notes, we’ll keep looking at the Sailors Reserve Boats example from the ERD notes, but now we’ll build a relational database corresponding to that ERD. Here is its schema diagram:
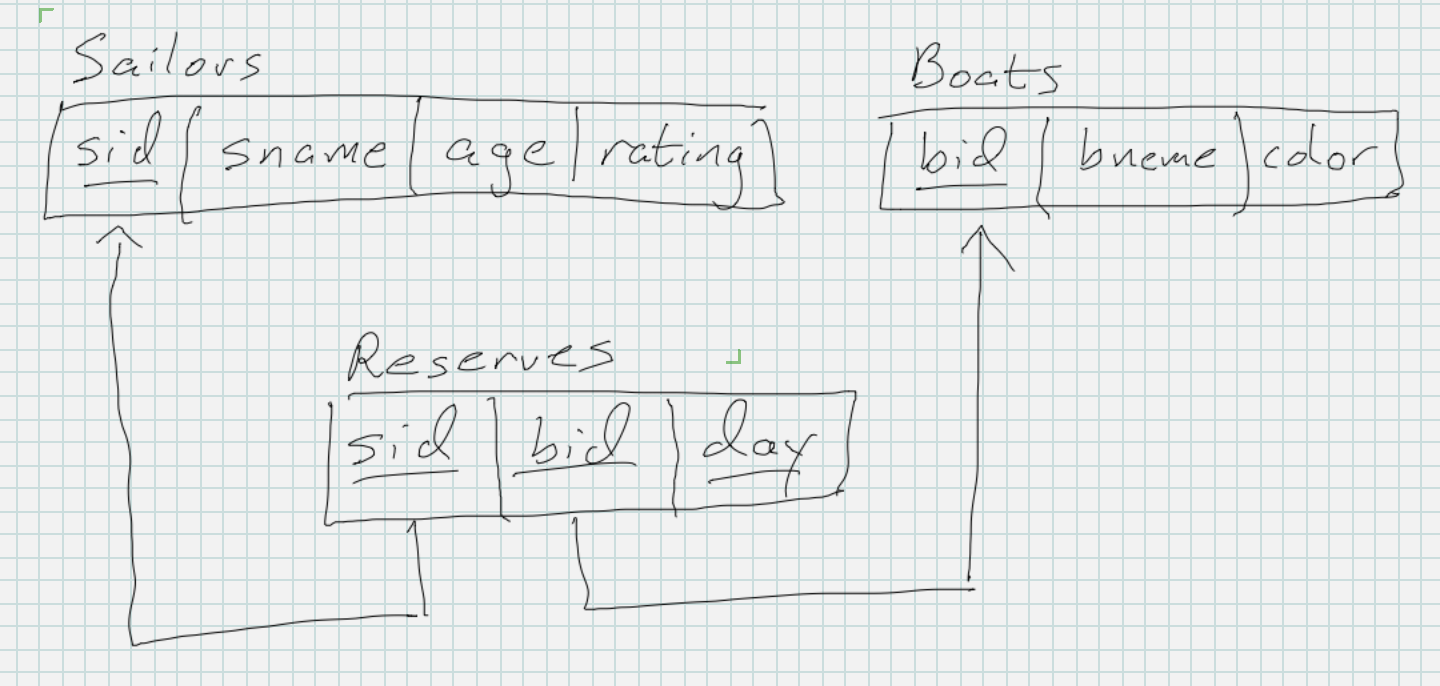
The CREATE TABLE statement below defines a new table called Sailors with 4 columns and a constraint that each row will have a unique value of sid because it is the primary key of the table.
CREATE TABLE Sailors ( sid INT PRIMARY KEY, sname TEXT, age REAL, rating REAL ) STRICT;
“Separated” means commas go between items in the “()”. So note that the last column, rating, does not have a trailing comma. Note that each column is defined by providing its name followed by its type, which is also sometimes referred to as its domain in the relational model. The ALL CAPS SQL convention helps in this case because you can easily tell which parts are SQL and which parts are names we provided for the schema. The type names will depend on the DBMS being used, so INT may work in some databases while INTEGER may be required in others. Some will allow either name.
Single-column PRIMARY KEYs have a special syntax in that we can just add PRIMARY KEY after the domain to tell the DBMS that this column is the PRIMARY KEY of the table. So for the Boats table we can do something similar. There is an alternate syntax for composite keys (more than one column making up the primary key) that will be illustrated shortly.
CREATE TABLE Boats ( bid INT PRIMARY KEY, bname TEXT, color TEXT ) STRICT;
In a different DBMS, we may have to use different data types. Below is the corresponding CREATE TABLE statement for MySQL and MariaDB, two DBMS’ which share a common code base and syntax. The main difference is that the text types typically have a width (number of characters in the string) specified. These widths exist because a lot of tabular data is of a certain format. For instance an SSN may be stored in the xxx-xx-xxxx format as an 11-character CHAR instead of as an integer.
CREATE TABLE Boats ( bid INT PRIMARY KEY, bname CHAR(20), color CHAR(20) );
The textual data in these two tables are declared as CHAR (short for character) types. CHAR types are different from the numerical types because we have to specify their width, the maximum number of character they are allowed to hold. That’s what the number in () indicates; the width is not optional. There is no simple color CHAR line that would work. We have to add the () with a number inside.
Below is a summary of the possible domains we’ll deal with in this course. There are other ones used in databases, but once you’ve gotten the hang of a few of them, it’s easy to learn the rest. We just focus on a simple set of them here to learn how to think about databases instead of simply memorizing the names of types or domains.
| SQLite TYPE NAME | MYSQL Type Name | Notes |
|---|---|---|
| INT | INT | Whole numbers |
| REAL | FLOAT | Decimal numbers. REAL works in MySQL also, but it is not technically the same type. FLOAT is single precision while REAL is double precision like a Java double. |
| TEXT | CHAR(x) or VARCHAR(x) | Words. Providing a whole number width x is mandatory for the CHAR and VARCHAR types. Those two types differ in that VARCHAR will allocate a variable amount of storage up to x characters while a CHAR will always allocate the full amount for x characters. |
| DATE | ||
| … | See the SQLite documentation for its types and here for MySQL data types |
The Reserves table is a different matter for two reasons. It contains foreign keys, so we must declare those constraints. It also has a composite primary key, so we can’t just put “PRIMARY KEY” after each column. We’ll have to declare that constraint separately. The general syntax for doing so is PRIMARY KEY (column1, column2, …). So we can start off with
CREATE TABLE Reserves ( sid INT, bid INT, day TEXT, -- this would be type DATE in MySQL PRIMARY KEY (sid, bid, day) ) STRICT;
This gets us the composite primary key, but now we must also add the two foreign key constraints. The general syntax for this is FOREIGN KEY (column1, column2, …) REFERENCES table(column1,column2, ….). So remembering that a foreign key means columns in a row in THIS table refer to other rows, we first provide the column(s) name(s) in this table (the Reserves table here), and then we provide the name of the other table that gets referenced followed by its column(s). Or in terms of the schema diagram, the first list of columns is the tail of the arrow and the second list is the tip of the arrow.
CREATE TABLE Reserves ( sid INT, bid INT, day TEXT, -- this would be type DATE in MySQL PRIMARY KEY (sid, bid, day), FOREIGN KEY (sid) REFERENCES Sailors(sid), FOREIGN KEY (bid) REFERENCES Boats(bid) ) STRICT;
Getting this FOREIGN KEY syntax down is important. Both sets of () are required, and in the () put either a single column name or a comma-separated list of columns for a composite key.
There are other constraints that can be described in create table, but they are not covered in this course. For instance, it is possible to indicate that values are required for a column. When values are not required, the DBMS may use NULL to indicate no value is stored in a column. Constraints may also indicate that a column’s value in a row must be unique even when it’s not the primary key.
Finally, and this is important, note how two dashes (–) are used to indicate a comment in SQL. Well-applied comments make our SQL statements more understandable!
The SQL DML – Adding rows to tables
The SQL DML is for adding and changing data, and these operations are often called updating and inserting data in the context of relational databases. The main statement we’ll see for the SQL DML is the INSERT INTO statement which we’ll also practice in the SQLite web front end. INSERT INTO is mostly straightforward, so we won’t have to dwell on it too much. It’s purpose is to add one or more rows of data to a specified table. Here is a sample INSERT INTO statement that adds a row of data to the Sailors table:
INSERT INTO Sailors (sid,sname,rating,age) VALUES
(22,'Dustin',7,45.0);Here is an INSERT INTO statement that adds three rows to the Boats table:
INSERT INTO Boats (bid,bname,color) VALUES
(101,'Interlake','blue'),
(102,'Interlake','red'),
(103,'Clipper','green');The tablename that will get the new row(s) comes after the INSERT INTO keywords. Typically the tablename is followed by a comma-separated list of column names that will receive the data in parentheses. This list is optional, but it’s a good idea to always include it. It is mandatory to include it in this course to demonstrate you understand its syntax and purpose. After the list of column names, the required keyword VALUES appears followed by one or more tuples of data. A tuple, recall is essentially a synonym for a row. It means a record or collection of values, and in this context its all or part of a row that will be added to a table. Like the column names, each tuple is enclosed in parentheses, but only the corresponding values for each column is supplied. It’s not necessary to include the column names again. The values should be in the same order as the column names were listed. There’s no requirement that the columns appear in the same order as in the CREATE TABLE statement, although they will be assumed to if the column names in parentheses are left out.
This list of column names is provided because it’s common to insert only a partial row of data. One reason some data may not be added is that the values are not known yet. For instance, if one is adding information about items for sale to track inventory, it may not have yet been determined how much the company will sell the items for. In that case, the corresponding column for the selling price may be left blank until then. Another common reason to leave a column out is because the DBMS may manage primary keys for you. If the row index 1,2,3,… is used as the primary key in a table, usually the DBMS adds the next correct value when data is inserted rather than the SQL programmer having to keep track of the next value to use. If columns are not supplied with new data and the DBMS does not autogenerate it, then the values in those columns will be NULL in the new rows. NULL is an SQL constant which is typically taken to represent the concept of missing or unknown data.
Optional: Referential Integrity
If we want to create an instance of the sailors reserves boats database from scratch, we will need to write three create table statements. If we use the one above for the Reserves table first before making any other tables, we’ll see this error message:
CREATE TABLE Reserves ( sid INT, bid INT, day TEXT, PRIMARY KEY (sid, bid, day), FOREIGN KEY (sid) REFERENCES Sailors(sid), FOREIGN KEY (bid) REFERENCES Boats(bid) ) STRICT; There was an error message from the database SQLITE_ERROR: sqlite3 result code 1: duplicate column name:
The message from SQLite doesn’t seem to make sense, for there are no duplicate column names based on what we know about the CREATE TABLE statement. The problem is that the foreign keys cannot be added, because the Sailors and Boats tables do not exist. So the sid and bid columns that should be in those tables are causing trouble for SQLite in this table since those tables don’t exist! The foreign keys need those tables to exist so that each table can have an id column that they can reference. The idea that something being referenced (pointed to) in a database must exist is called referential integrity. In order to create the Reserves table, the Sailors and Boats tables must exist. Because those two tables don’t exist, it would be impossible for the sid and bid foreign key columns in the Reserves table to hold any values. There are no sids to refer to because there are no sailors since there’s no Sailors table!
An even stronger form of referential integrity can be described in which the Sailors and Boats tables exist, but the sid and bid foreign key columns in the Reserves table violate referential integrity. Imagine the Sailors table contains only the one row (22,’Dustin’,7,45.0) describing the sailor with sid = 22. If the Reserves table contains any other sid value than 22, then it has violated referential integrity. Since Reserves(sid) is a foreign key, it is a shorthand for a row in the Sailors table. It’s only permissible, then, for it to have sid values that appear in the Sailors table. Many DBMSs will enforce these constraints on your data. They would prevent you from adding a row to Reserves if it refers to a Sailor row that does not exist, for instance. Interestingly, not all DBMSs do this, though. Enforcing such constraints may be time-consuming, and many DBMS programs simply do not dedicate CPU cycles to this kind of functionality.
Moreover, some DBMS’s make this enforcement optional. It can be turned on or off. It’s common in real databases with many tables for two tables to have foreign keys referring to each other. In this case, the circular dependency means it may never be possible to add data when enforcement of referential integrity is activated. A common solution is to turn off enforcement until the tables are populated with data and then activate enforcement again.