INFO-I427 covers the topic of information retrieval (IR). IR is, to put it simply, a discipline where the goal is to answer a user’s information need. The information need is answered by returning the relevant information. In I308, we learn to use the structured query language (SQL) to answer a query on a database. IR is more complicated than answering simple queries on a database in these key ways:
• The user’s information need may not be as precisely stated as one for an I308 query can be.
• The dataset that information is being retrieved from (to answer the information need) may be consid-erably more complicated than a simple relational database.
Because of these differences, IR adopts a different terminology and approach compared to simple querying on a database. First, rather than a database returning the results, a search engine returns the results. The objects returned by the search engine are not tables, rows, or database reports; instead they are documents. The idea of a document in IR is a general one. It may include text documents, web pages, medical reports, financial records, and any other number of possibilities depending on the particular search engine. Documents in a search engine are analogous to rows in a table in some sense. Some specialized vocabulary has arisen around search engines and IR. The set of documents to be searched is called the corpus. A search engine is thus a means to answer queries against not a database but against a corpus. It’s possible the corpus will be stored in a database, but it doesn’t really matter either way. The search engine worries about these details, organizes the corpus, receives searches from end users, and returns the documents from the corpus that match the results.
These distinctions are commonly summarized in terms of the data operated on. Relational databases obey a schema, and the schema describes very precisely the kind and size of data it contains. Such data is said to be structured because its “shape” is known so precisely. In contrast, a corpus of documents is called unstructured data. Not every document need be the same size, and different documents may even be in different formats or be different kinds of data. A corpus is like a big pile of information that the search engine tries to make sense of. And on top of all that the information needs of the user are less precise. In relational databases, the query may be stated like ”return IDs of all patients with heart disease” which is a precise statement for the right schema. In IR, the search terms “heart disease” could mean find documents about heart disease, find patients with heart disease, reports containing the phrase heart disease, or any combination of these things. IR is a less precise, and consequently more challenging, field in general since the approaches used must be more robust to deal with these additional complexities.
Regardless of the kind of corpus being searched, documents in IR contain words. End users want to search documents based on their content—based on the words they contain. Thus the words in all the documents in the corpus constitute the set of all possible search terms—the lexicon. The lexicon, or vocabulary, is the set of all possible search terms for a corpus. Fig. 1 illustrates this idea with a simple corpus containing 3 short documents. Note that the documents are simply text content; the format they were stored in (Word, HTML, PDF, etc.) is irrelevant here. The lexicon contains the set of possible search terms. The notion of a set means that duplicates are not allowed. A word appearing more than once in the corpus appears only once in the lexicon. Also note that the capitalization is irrelevant. Words appearing at the start of a sentence are normalized by converting them to lowercase, and even proper names are so normalized in this example. Note that the concept of a document is essentially plural: the document may hold many possible search terms. To describe exactly which ones it does hold, we need to separate the text of the document into its individual search terms. This separation process is called tokenization and each resulting output is called a token.

Figure 1: The lexicon or vocabulary is the set of all possible search terms for a given corpus.
Search Engines
In I427, we will implement two different search engines. The first will be an engine allowing the user to return tweets from Twitter. The second, more complex engine will be a web search engine that returns web pages as results, similar to Google, Bing, or others. Note that the first sentence of this paragraph states that we will implement the search engine; this means that we will program them. In addition to learning the concepts of IR and the components of a search engine, we will have to write code that leads to the search engine performing its task of returning search results (documents) to the user in response to their information need.
A search engine is typically broken up into the components shown in Fig. 2. Each of them is described below. A key component of a search engine is the inverted index or more simply, just the index. It allows one to look up by search terms and retrieve related documents, similar to how an index in the back of a book lets you find page numbers related to the topic one looks up. The index cannot return results by itself, however. It must have access to the corpus in order to return documents, and it must have a way to convert the user’s information need into terms to look up in the index. The query engine is responsible for processing the users’ information need in this way. Finally, the corpus must be assembled in the first place. The crawler is responsible for processing documents for inclusion in the corpus.
The direction(s) of the arrows in Fig. 2 have meaning. They show the flow of information in a search engine (and as such are an example of a data-flow diagram). The crawler gathers document by crawling in order to assemble the corpus. The corpus’ contents are used to build the inverted index, and the inverted index’s data is used by the query processor to assemble search results. The query processor needs to be aware of the information need from the end user, and the query processor must return results to the end user. Thus, there is a two-way data exchange between the end user and the query process. Finally, the engine often returns documents to the end user, and the documents are not stored in the index; they are part of the corpus. The corpus also provides data to the query processor! The complete process of receiving and information need and returning results occurs in this order: 1. the end user specifies the information need, 2. The query processor uses the index to assemble preliminary results, 3. The results are returned to the end user. Unsophisticated search engines will carry out steps 1-3 as described. More sophisticated engines will process or refine the preliminary results before returning them to the end user.
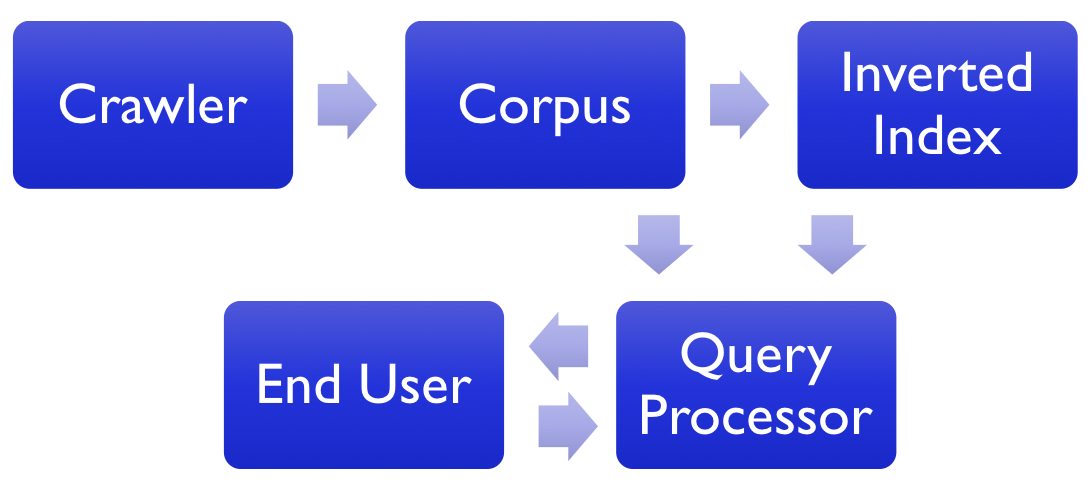
Figure 2: The data flow of a typical search engine showing the four main software components (the End User is wetware and not software).