If an application is using a DBMS for persistence, the app and the database must be able to communicate with each other. This communication can be categorized as 4 different kinds of operations:
- CREATE – add new information
- READ – retrieve information
- UPDATE – change existing information
- DELETE – remove information
Many apps do nothing but variations on these 4 things, and these kinds of apps are called CRUD apps. If you are an INFO major and become a software developer, your future is likely to be writing these apps until the end of time!
Canvas can be thought of as a CRUD app. If you access the I308 Canvas site to hand in an assignment, Canvas will READ the I308 course material to show you the assignment page. Canvas will CREATE a new assignment submission when you hand in. If you hand in a new version later, canvas will UPDATE your submission, and so on.
Other apps act the same way. Billable events (the most important kind of events) in a medical office have ICD-10 codes that describe the nature of the event. Part of a patient’s record may include a list of these events which can be updated or deleted as the situation warrants. Any display of the record on the screen is a read of the record, and new patients or visits to the medical office correspond to the creation of new records in the system.
Records and Relationships
To be able to do these wonderful CRUD things, an app must have an idea of what kind of data it will keep track of. Canvas has a notion of users, courses, assignments, assignment submissions, comments, pages, … Each one of these objects must be stored in a database, and each one of these objects will likely consists of a collection of related information. A user will have a username, password, email address, etc. A course will have a course number, section number, title, semester, … Assignments will have a title, content, due date, … Such groups of related information is called a record, and records are one of the fundamental concepts in a database. The items of information that are related are often called attributes. In the Canvas user example, we would say there is a username attribute, password attribute, etc.
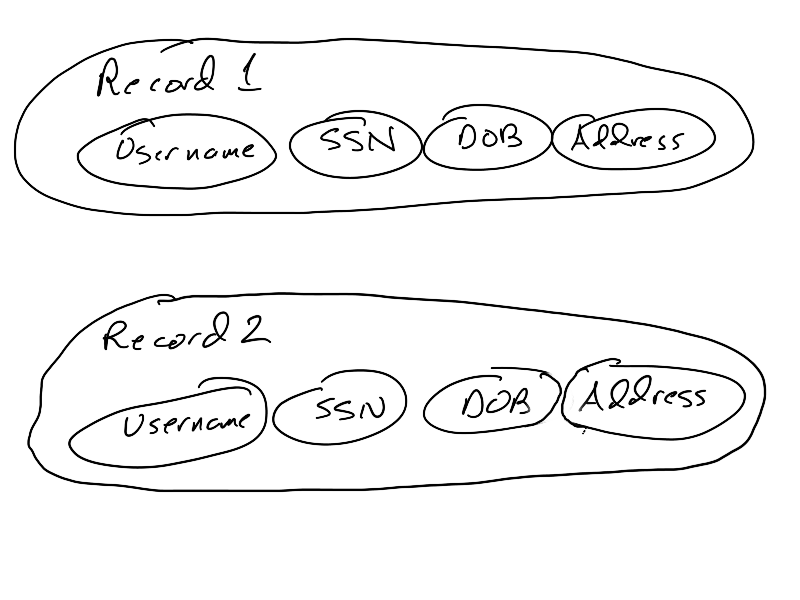
Moreover, there may be relationships that connect records together. An assignment is related to a course (because different courses have different assignments). An assignment submission is related to the assignment and to the user who submitted it. Relationships are connections between these objects.
Three Views of Data & Data Models
A description of an app’s information needs in terms of records and relationships is called a data model. There are different ways to describe the data model at different levels of detail, and these different ways are often referred to as “views of data” or as a specific kind of data model. Typically, three different levels of detail are used:
- The conceptual view of data with its corresponding conceptual data model. This is the least detailed, highest-level view.
- The logical view of data with a corresponding logical data model describes the way a DBMS presents the data to the app or a user. Different DBMS’s use different logical data models.
- A physical view of data or a physical data model provides the lowest-level, most detailed view of data.
In other INFO courses like I210 or I211, two programming design approaches are considered: top-down and bottom-up. Top down design means to start with the big picture first and gradually incorporate more details as a plan is developed. Bottom-up design is the opposite approach. It means to begin programming right away without a clear plan in place and let the big-picture strategy work itself out. Top-down design is considered a best practice while bottom-up design is not. Similarly with data modeling (the process of determining what information and organization needs to stored), it’s considered a best practice to develop a strategic approach and worry about the details last. The details involve actually storing the data on the computer, so it’s typical to first write down the information needs and develop a description of what information will be stored. This first part of the process is conceptual data modeling. Later in the course, we’ll create Entity-Relationship Diagrams that are a conceptual description of the data.
Once the conceptual description is created, it’s appropriate to consider a lower-level of detail. There are many different kinds of databases, and each usually has a supported way of organizing the data. This way of organizing doesn’t necessarily describe how the computer will store the data. It instead describes how the programmer, developer, or records specialist can think about the data and communicate with the DBMS. This view of data is the logical level, and it is described in more detail in the next section.
Many different DBMSs may use the same logical view of the data, but they may take radically different approaches to actually storing it. The details of how it’s actually stored comprise the physical view of the data. For instance, SQLite is a single-file database. All the records are stored in one file (up to a limit of 1 PB or so) in SQLite. Most other DBMSs take a different approach and store records in multiple files and often optimize this storage depending on the server environment in which they are running. All these use the same logical model (one called the relational model) while difering in their physical details.
An advantage of the three-view approach is that each level is independent of the other. The same conceptual data model can be converted into different logical data models without affecting the conceptual view. Similarly, the same logical data model can be implemented with many different physical models.
Logical Data Models
We will learn about the four logical data models listed below in this course, but we will only deal with the first three right now, saving the fourth one for later:
- The flat model is a data model with one kind of record where there is no particular relationship between the records.
- A hierarchical data model is characterized by having a single kind of record with a parent-child (one-to-many) relationship between records.
- The network data model allows any record to be related to any other, and this is called a many-to-many relationship.
- The relational data model is the model used by most modern databases. It is sufficiently important and complicated that we will define it separately later in the course. Most of I308 involves learning about the relational data model and its consequences.
The order given above is roughly chronological. The flat model is the oldest and the relational model is the newest. The relational model is not that new, though, for it was invented in the late 1960’s. Each of the first three was used in early DBMS’s that were developed in the 1960’s.
To distinguish between the first three kinds of data models, we can note that they each differ in terms of the relationships that are allowed between records. If we identify the record used in the data model and the allowed kind of relationship, then we can determine which data model is being used. To start off, if there is no relationship between the records, then it’s called the flat model. When there is a relationship between the records, we need to determine which kind it is.
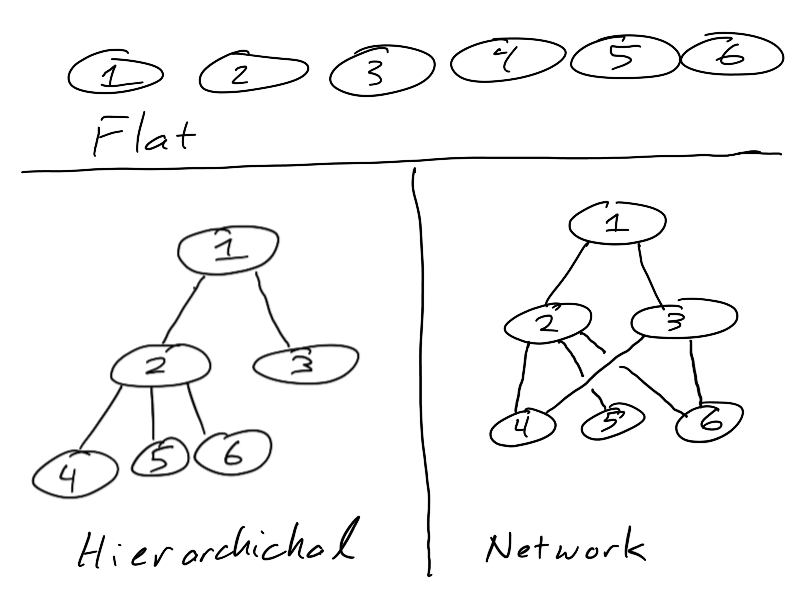
A relationship always involves connections between pairs of records. The two kinds of relationships described above (one-to-many and many-to-many) differ in their cardinality (how many records are involved). A one-to-many relationship is also often called a parent-child relationship. Parent and child here is used in the computing context and not the context of a family of humans. In computing, there can be only parent, but the parent can have many children. One parent can have many children, but a child can have at most one parent. The “at most one” in the previous sentence is because hierarchies (also called trees in computing) have one special node called the root that begins the whole thing. In the Hiearchical diagram above, record 1 is the root node, and the records are organized to show the root at the top, the children of the root one level beneath, and the grandchildren a further level down.
A hierarchical data model is the same because not every record must have a parent, but if a record does, it can have only one–a record can have at most one parent. A parent record in the hierarchical data model can have many children, so a hierarchical data model looks like a tree if it has one root record or a forest if it has more than one. This is the definition of a one to many relationship between records.
The network data model has a more general kind of relationship. Any record can be connected to any other, and any record can be connected to more than one record. “Many” in database-speak means “more than 1”, so a many-to-many relationship is one where any record can be connected to more than one record. Since there is no “at most one parent” requirement, a network data model doesn’t have to have a root. In the diagram above, there is no possible way to move the records around while maintaining the connections between them to show that a parent-child relationship holds for each record, so it must be a network. In real life situations, one would know what constraints the relationship must obey, and from those constraints one can determine what kind of relationship is possible between the records. Some examples are shown at the end of these notes.
Although hierarchical and network data models are allowed to have relationships between records, they don’t have to. So either of those models can be used to describe a set of records without relationships; i.e. they are both general enough to incorporate the flat data model. Remember the flat data model is the oldest, so the hierarchical data model was an improvement on it that was “backwards compatible” and could still hold all the original kinds of data.
In the same sense, a network data model can be used to hold a hierarchy, for any hierarchy is a kind of network. In other words, the hierarchical data model generalizes the flat one, and the network data model generalizes the hierarchical one. Later we’ll see that the relational data model is the most general one of all.
Exercises
We are storing data about employees including name, SSN, date of birth, and address. What logical data model is appropriate?
Since there is no indication that employee records have any kind of connection, there is no relationship between records. The flat model is appropriate.
We are storing data about employees including name, SSN, date of birth, address, and supervisor. A supervisor is an employee that several employees may report to. An employee has at most one supervisor. What logical data model is appropriate?
The supervisor supervises many employees. An employee has at most one supervisor. The relationship described is a parent-child one, so the hierarchical data model is most appropriate.
We are storing data about employees including name, SSN, date of birth, address, and projects. An employee works on projects with other employees. An employee may work on more than one project, and multiple employees tend to work on the same project. What logical data model is appropriate?
Any two employees may be connected by virtue of working on a project together, so the network data model works best for this many-to-many relationship.